
AI models are only as good as the data they learn from. Every image classification system, voice assistant, autonomous vehicle, and fraud detection algorithm depends on one thing: accurately labeled training data. Without it, even the most sophisticated model architecture produces unreliable results.
AI data labeling — the process of tagging, annotating, and classifying raw data so machine learning models can learn from it — is now one of the most strategically important operations in AI development. This guide covers everything you need to know about AI data labeling services: what they are, how they work, what types exist, how to evaluate providers, and what separates high-quality labeled data from the kind that breaks your model.
What Are AI Data Labeling Services?
AI data labeling services are specialized operations that prepare raw data — images, video, text, audio, LiDAR point clouds — for use in machine learning model training. The process involves human annotators, AI-assisted tools, or a combination of both applying structured labels, tags, bounding boxes, or classifications to each data element according to a defined taxonomy. AI data labeling services, a core part of data annotation services, transform raw text, images, audio, and video into accurately tagged datasets that improve machine learning model performance.
The result is a labeled dataset: a structured collection of data where every element carries machine-readable information about its content, category, or characteristics. When a self-driving car model learns to recognize pedestrians, or a medical AI learns to identify tumors in radiology images, it’s learning from millions of examples that someone labeled correctly.
| WHY DATA QUALITY IS THE BOTTLENECK
Research from MIT found that up to 94% of AI failures in production can be traced to poor-quality training data — not model architecture flaws. The model learns exactly what it’s shown. Label incorrectly at scale, and the model errors at scale. |
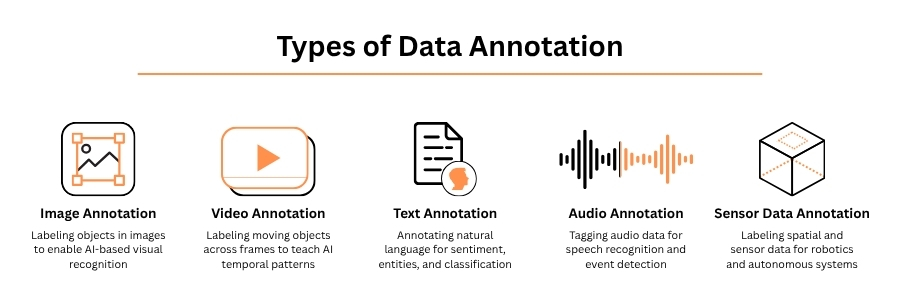
Types of AI Data Labeling
| Labeling Type | What It Annotates | Common AI Applications |
| Image Annotation | Objects, boundaries, pixels in photos | Computer vision, autonomous driving, retail AI |
| Video Annotation | Objects across frames, motion tracking | Surveillance, sports analytics, AV systems |
| Text Annotation | Sentiment, intent, entities, relationships | NLP, chatbots, search engines, legal AI |
| Audio Annotation | Speech, sounds, speaker diarization | Voice assistants, transcription, call analytics |
| LiDAR / 3D Annotation | Point clouds, 3D bounding boxes | Autonomous vehicles, robotics, mapping |
| Medical Annotation | Anatomy, pathology, diagnostic markers | Radiology AI, surgical robotics, diagnostics |
How AI Data Labeling Services Work
Professional data labeling operations follow a structured workflow designed to produce consistent, auditable, and reproducible results. The typical pipeline has five stages:
- Data ingestion and preprocessing — Raw data is received, cleaned, formatted, and organized into annotation batches.
- Taxonomy and guideline development — The annotation schema (what to label, how to label it, edge case handling) is documented and approved.
- Annotation — Human annotators or AI-assisted tools apply labels according to the taxonomy. Complex tasks typically use multiple independent annotators.
- Quality assurance — Completed annotations are reviewed against ground tr
uth, inter-annotator agreement is measured, and inconsistencies are corrected. - Delivery and integration — The labeled dataset is formatted for training pipeline ingestion and delivered with quality metrics documentation.
“The difference between a 95% accurate model and a 99% accurate model is almost entirely in the training data, not the algorithm. Investing in annotation quality is investing in model performance.”
— ML Engineering Lead, Fortune 500 AI Team
Data annotation services work by collecting raw data, applying precise labels through human experts and AI-assisted tools, validating quality, and delivering structured datasets ready for model training and optimization.
Human Labeling vs. AI-Assisted Labeling vs. Automated Labeling
| Approach | Best For | Common AI Applications |
|---|---|---|
| Image Annotation | Objects, boundaries, pixels in photos | Computer vision, autonomous driving, retail AI |
| Video Annotation | Objects across frames, motion tracking | Surveillance, sports analytics, AV systems |
| Text Annotation | Sentiment, intent, entities, relationships | NLP, chatbots, search engines, legal AI |
| Audio Annotation | Speech, sounds, speaker diarization | Voice assistants, transcription, call analytics |
| LiDAR / 3D Annotation | Point clouds, 3D bounding boxes | Autonomous vehicles, robotics, mapping |
| Medical Annotation | Anatomy, pathology, diagnostic markers | Radiology AI, surgical robotics, diagnostics |
Most production-grade annotation programs use AI-assisted workflows — where a pre-trained model generates draft annotations that human reviewers correct and approve. This approach can reduce annotation time by 40–60% while maintaining human-level quality standards. In computer vision guide, human labeling ensures precision, AI-assisted labeling boosts speed with oversight, and automated labeling enables large-scale annotation, balancing accuracy, efficiency, and scalability for model training.
Key Quality Metrics in AI Data Labeling
| Metric | What It Measures |
| Inter-Annotator Agreement (IAA) | Consistency between different annotators on the same data — target >85% for most tasks |
| Precision / Recall | Accuracy of labels against ground truth benchmarks |
| F1 Score | Harmonic mean of precision and recall — balanced accuracy measure |
| Defect Rate | Percentage of annotations requiring correction after QA review |
| Label Consistency | Whether edge cases are handled the same way across the dataset |
How to Choose an AI Data Labeling Service Provider
Not all labeling providers are equal. Here’s what separates reliable partners from vendors who deliver quantity over quality:
- Domain expertise — Does the provider have annotators trained in your data type? Medical imaging requires clinical knowledge. Autonomous vehicle annotation requires understanding of traffic scenarios.
- Quality assurance infrastructure — What percentage of annotations are QA reviewed? Are QA metrics shared with clients? What’s the inter-annotator agreement on your task type?
- Scalability — Can the provider scale from 10,000 to 10 million annotations without quality degradation? What’s their ramp timeline?
- Data security — What data handling protocols apply to sensitive or proprietary training data? Are they SOC 2 / ISO 27001 certified?
- Workflow transparency — Do you have visibility into annotation progress, quality metrics, and annotator consistency in real time?
- Tooling — Do they use their own annotation platform or a leading tool like Scale AI, Labelbox, or CVAT? Does it integrate with your ML pipeline?
Choose an AI data labeling service provider with proven expertise in various field like healthcare data annotation, retail, and other with strong quality controls, domain-trained annotators, data security compliance, and scalable delivery for high-accuracy AI model training.
Common Mistakes in AI Data Labeling Programs
- Unclear annotation guidelines — Ambiguous taxonomies produce inconsistent labels that poison model training. Every edge case must be documented before annotation begins.
- Insufficient QA coverage — Reviewing only 5% of annotations misses systematic errors. Production-grade programs review 15–30% of all annotations.
- Ignoring class imbalance — If 95% of your training data represents one class, your model will learn to predict that class almost exclusively.
- Assuming more data is always better — 100,000 high-quality annotations outperform 1 million inconsistent ones. Quality beats quantity.
- No feedback loop — Annotation programs that don’t feed model performance back to annotators cannot improve over time.
Common mistakes in AI data labeling programs include unclear guidelines, inconsistent annotations, poor quality checks, and underutilizing human-in-the-loop workflows, which are essential for maintaining accuracy and model reliability.
The Future of AI Data Labeling
The demand for labeled data is accelerating faster than human annotation capacity can scale. Several developments are reshaping the field:
- Synthetic data generation — AI-generated synthetic datasets are increasingly used to augment real annotated data, particularly for rare scenarios in autonomous driving and medical imaging.
- Foundation model pre-annotation — Large foundation models (GPT-4, SAM, etc.) can pre-annotate with increasing accuracy, reducing the human annotation burden to validation and correction.
- Active learning — ML systems that identify which unlabeled examples would provide the most training value, directing annotation effort where it matters most.
- Multimodal annotation — Growing demand for annotation that spans text, image, audio, and video simultaneously for multimodal AI systems.
| “Data is the new oil. But unlike oil, data doesn’t refine itself. Quality annotation is the refinery.”
— Andrew Ng, AI Pioneer and Founder, DeepLearning.AI |
Key Takeaways
- AI data labeling services prepare raw data for machine learning model training through structured annotation workflows.
- Quality metrics — inter-annotator agreement, defect rate, precision/recall — determine whether labeled data produces reliable models.
- The best annotation programs combine AI-assisted pre-labeling with human expert review (human-in-the-loop).
- Provider selection should prioritize domain expertise, QA infrastructure, scalability, and data security over price.
- The field is evolving rapidly — synthetic data, foundation model pre-annotation, and active learning are reducing annotation costs while improving quality.
Accelerate your AI success in 2026 with expert data labeling solutions. Partner with us for accurate, scalable, and high-quality annotation services that power smarter, more reliable AI models.
Sumanta Ghorai
Sumanta Ghorai is a CX and BPO marketing professional specializing in go-to-market strategy, thought leadership, and presales storytelling for global enterprises. At Fusion CX, he works closely with business and delivery leaders to translate complex CX and AI-driven capabilities into clear, outcome-focused narratives across telecom, utilities, and technology-led industries.